



لقد أصبح تعلّم الآلة منتشرًا في كل مكان من خلال المشاركة في مسار التعلم الآلي وقد طغى على العديد من جوانب شؤوننا والترفيه اليوم؛ بدءًا من خوارزميات تصنيف محركات البحث وتحليل صور الأشعة السينية وحتى توصيات مقاطع الفيديو على YouTube. ومع هذه المجموعة الواسعة من التطبيقات، من المتوقع أن يصل سوق التعلم الآلي العالمي إلى 209.91 مليار دولار بحلول عام 2029، من 21.7 مليار دولار في عام 2022، وفقًا لبحث أجرته Fortune Business Insights. في هذه المقالة من مدونة Akwad، نحاول مراجعة 10 من أشهر خوارزميات التعلم الآلي معًا ومناقشة أداء كل منها.
ما هو التعلم الآلي؟
تعلّم الآلة (ML) هو فرع من فروع الذكاء الاصطناعي وعلوم الكمبيوتر الذي يركز على استخدام البيانات والخوارزميات لتعلم كيفية القيام بالأشياء، وزيادة دقتها تدريجياً بمرور الوقت. تتواجد خوارزميات التعلم الآلي في العديد من البرامج والأدوات التي نستخدمها يومياً؛ مثل محرك بحث جوجل. أحد أسباب القوة المتزايدة لمحرك البحث هذا هو القدرة على تعلم ترتيب الصفحات، والذي يتم بدون برامج مكتوبة مسبقًا. تُستخدم هذه الخوارزميات لأغراض مختلفة مثل استخراج البيانات والتحليل ومعالجة الصور والتنبؤ. الميزة الرئيسية لاستخدام التعلم الآلي هي أنه بمجرد أن نعلم الآلة ما يجب القيام به؛ ثم سيقوم الجهاز بمعالجة المعلومات وتنفيذ المهام تلقائيًا.
كم عدد أنواع خوارزميات التعلم الآلي الموجودة لدينا؟
ببساطة، تشبه خوارزميات التعلم الآلي التعليمات التي تسمح لأجهزة الكمبيوتر بتعلم القيام بالأشياء واستخدام البيانات والتحليلات لإجراء التنبؤات. فبدلاً من إخبار الكمبيوتر بوضوح بما يجب عليه فعله، فإننا نعطيه كمية كبيرة من البيانات لاكتشاف الأنماط والعلاقات. حاليًا، لدينا ثلاثة أنواع من خوارزميات التعلم الآلي، وهي:
التعلم تحت الإشراف
التعلم الخاضع للإشراف هو نوع من خوارزمية التعلم الآلي حيث نستخدم مجموعات البيانات المصنفة لتدريب النموذج. الهدف من خوارزمية التعلم هذه هو التعرف على الأنماط بين البيانات المدخلة، مما يسمح لها بعمل تنبؤات أو تصنيفات للبيانات الجديدة. يتضمن هذا النوع خوارزميتين للانحدار والتصنيف.
التعلم غير الخاضع للرقابة
التعلم غير الخاضع للرقابة هو نوع من خوارزميات التعلم الآلي حيث تستخدم الخوارزميات بيانات ضخمة وغير موقعة للعثور على الأنماط أو البنية أو العلاقة ضمن مجموعة من المعلومات. في هذه الخوارزميات، يستخدم الجهاز تحليل البيانات دون فئات أو تسميات محددة مسبقًا للتنبؤ بالأداء والتحقق منه. يتضمن هذا النوع من خوارزمية التعلم الآلي نوعين من التجميع وتقليل الأبعاد.
التعلم المعزز
التعلم المعزز هو نوع من خوارزمية التعلم الآلي حيث يتعلم الوكيل اتخاذ القرارات الصحيحة من خلال التفاعل مع البيئة المحيطة به. هدف الوكيل هو اكتشاف التكتيكات المثلى لتعظيم المكافآت بمرور الوقت من خلال التجربة والخطأ. غالبًا ما يُستخدم التعلم المعزز في السيناريوهات التي يحتاج فيها الوكيل إلى تعلم كيفية التنقل في بيئة ما، أو ممارسة لعبة، أو إدارة الروبوتات، أو إصدار الأحكام في مواقف غير مؤكدة.
أشهر خوارزميات التعلم الآلي
أشهر خوارزميات التعلم الآلي هي التعلم الخاضع للإشراف وغير الخاضع للإشراف والتعلم المعزز، والتي سنذكرها أدناه.
1. الانحدار الخطي
تسمى هذه الخوارزمية “الانحدار الخطي” أو “التنبؤ الخطي” باللغة العربية. يستخدم الانحدار الخطي للتنبؤ بالقيم المستمرة مثل أسعار المنازل أو المبيعات أو الرواتب. يعمل الانحدار الخطي من خلال إيجاد علاقة خطية بين المتغير التابع (ما تريد التنبؤ به) ومتغير مستقل واحد أو أكثر (الأشياء التي يمكن أن تؤثر على المتغير التابع).
يساعدنا الانحدار الخطي على فهم كيف يمكن للعوامل المختلفة أن تؤثر على سعر الشيء والتنبؤ بالعلاقة بين البيانات بناءً على ذلك. إنه مثل العثور على اتجاه أو نمط في البيانات يساعدنا على إجراء تخمينات مدروسة حول المستقبل. تُستخدم هذه الخوارزمية للتنبؤ وليست مفيدة لتصنيف المدخلات.
المثال التالي يتنبأ بمبيعات الألعاب بناءً على ميزاتها. تخيل أن لديك مجموعة من الألعاب وتريد أن تعرف المبلغ الذي يمكنك بيعها به. يشبه الانحدار الخطي محاولة العثور على خط مستقيم يمثل العلاقة بين سعر اللعبة وخصائصها المختلفة، مثل الحجم أو اللون أو العمر.
لذلك، عليك أن تبدأ بجمع البيانات حول كيفية بيع كل لعبة في الماضي، بالإضافة إلى ميزاتها. بعد ذلك، يمكنك رسم رسم بياني خطي يناسب جميع نقاط البيانات بأكبر قدر ممكن. يوضح هذا الخط العلاقة بين مميزات اللعبة وسعرها.
2. الانحدار اللوجستي
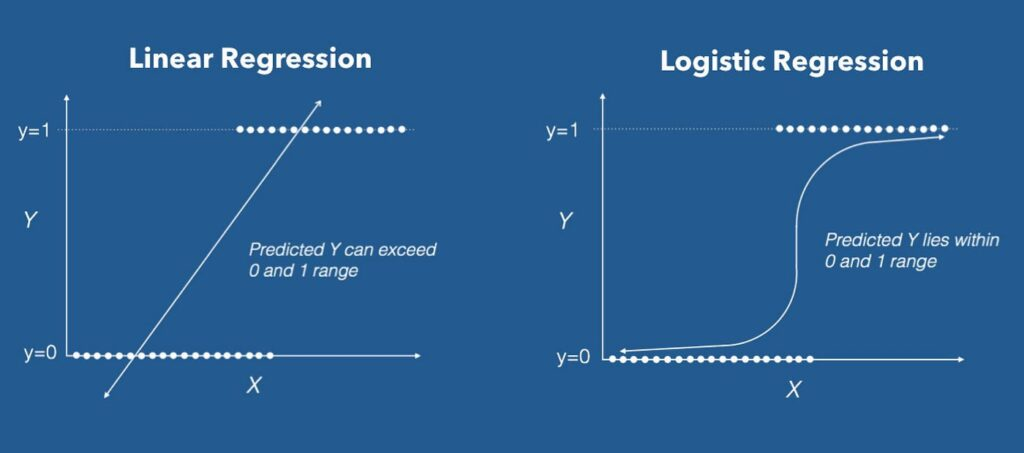
الانحدار اللوجستي هو نوع من خوارزمية التعلم الخاضع للإشراف التي يمكن استخدامها للتنبؤ بالنتائج الثنائية، مثل ما إذا كان العميل يشتري منتجًا أم لا، أو ما إذا كان الشخص مصابًا بمرض أم لا، أو ما إذا كان الطالب يحصل على درجة النجاح أم لا.
يتخذ الانحدار اللوجستي قراراته بناءً على إيجاد العلاقة بين المتغير التابع (النتيجة الثنائية التي تريد التنبؤ بها) وواحد أو أكثر من المتغيرات المستقلة (الأشياء التي يمكن أن تؤثر على المتغير التابع).
على سبيل المثال، تخيل أن لديك مجموعة بيانات للعملاء وتاريخ الشراء الخاص بهم. أنت الآن تريد استخدام مجموعة البيانات هذه لتدريب نموذج الانحدار اللوجستي للتنبؤ بما إذا كان العميل الجديد سيشتري منتجًا أم لا.
يجد نموذج الانحدار اللوجستي علاقة بين تاريخ شراء العميل وما إذا كان قد اشترى المنتج أم لا. على سبيل المثال، قد يدرك النموذج أن العملاء الذين اشتروا منتجات مماثلة في الماضي من المرجح أن يشتروا المنتج الجديد أيضًا.
بمجرد تدريب النموذج بواسطة خوارزمية الانحدار اللوجستي، يمكنك استخدامه للتنبؤ بما إذا كان العميل الجديد سيشتري المنتج أم لا من خلال إعطائه سجل الشراء الخاص بالعميل.
يمكن استخدام هذه الخوارزمية لتطبيقات مثل تصنيف البريد الإلكتروني العشوائي ومراقبة الجودة في خط الإنتاج. هذا النموذج هو الخيار الأفضل لتصنيف قيم الإدخال.
3.(KNN (K-nearest Neighbour
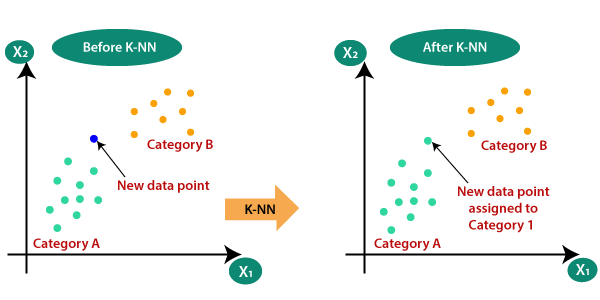
في هذه الخوارزمية، يعتمد قرار النموذج على أقرب جيران للنقطة الجديدة. K هي في الواقع مجموعة من أقرب الجيران الذين يمكنهم مساعدة النموذج في تسمية النقطة الجديدة ووضعها في مجموعة معينة. في الواقع، يتعلم النموذج التعرف على ميزات النقطة الجديدة من خلال النظر إلى جيرانها.
يمكن لهذا المثال الواقعي البسيط أن يوضح كيفية عمل خوارزمية KNN. ترغب إحدى الشركات في تصميم نظام توصية بالمنتج لموقعها الإلكتروني. تمتلك الشركة قاعدة بيانات لتاريخ شراء العملاء ومعلومات المنتج. يمكنه الآن استخدام مجموعة البيانات هذه لتدريب نموذج KNN. يتعلم هذا النموذج العلاقة بين المنتجات التي اشتراها العملاء في الماضي والمنتجات التي من المحتمل أن يشتروها في المستقبل. بعد تدريب النموذج، يمكن للشركة استخدامه للتوصية بالمنتجات للعملاء الجدد بناءً على تاريخ الشراء الخاص بهم.
KNN هي خوارزمية بسيطة ومتعددة الاستخدامات يمكن استخدامها لمهام التصنيف والتنبؤ. غالبًا ما تُستخدم خوارزمية التعلم الآلي هذه لتصنيف الصور والنصوص واكتشاف الاحتيال. KNN هي أفضل خوارزمية لتجميع القيم.
4.K-Means Clustering
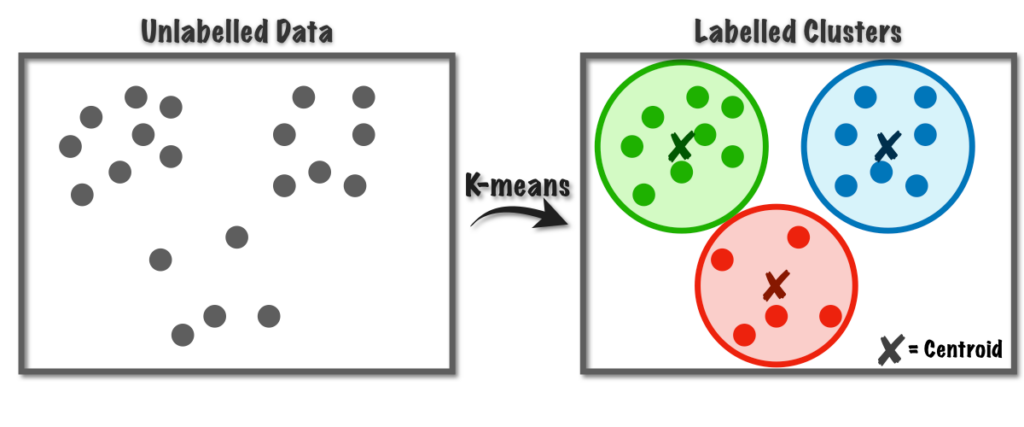
يعد تجميع K-Means أسلوبًا تعليميًا غير خاضع للرقابة يمكن استخدامه لتجميع البيانات في مجموعات. هذه الخوارزمية تشبه KNN؛ لأنه لا يزال يستخدم أسلوب الجوار الأقرب ويجمع الجيران مع بعضهم البعض. المجموعات هي مجموعات من نقاط البيانات المتشابهة مع بعضها البعض والمختلفة عن نقاط البيانات الموجودة في المجموعات الأخرى. K-يعني التجميع يبدأ باختيار مركز الكتلة، k. ثم يقوم بشكل عشوائي بتعيين كل نقطة بيانات إلى إحدى مجموعات k. ثم يقوم بحساب النقطه الوسطى لكل مجموعة. بمجرد حساب المراكز، تقوم K-Means Clustering بتعيين كل نقطة بيانات إلى المجموعة ذات المركز الأقرب. يتم تكرار هذه العملية حتى لا يتبقى أي نقاط بيانات. في هذه الخوارزمية، تكون نقاط البيانات في كل مجموعة متشابهة قدر الإمكان مع بعضها البعض، وفي نفس الوقت تكون مختلفة قدر الإمكان عن نقاط البيانات الموجودة في المجموعات الأخرى.
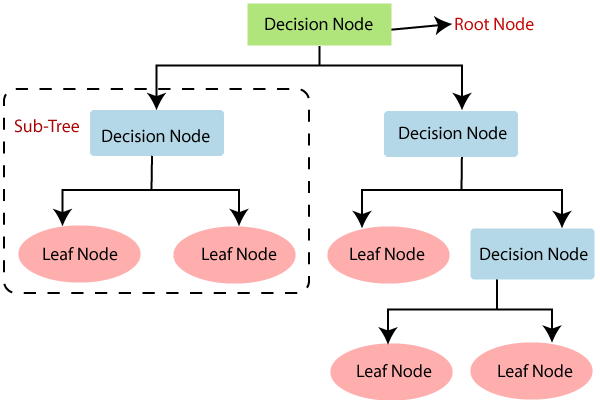
5.Decision Tree
شجرة القرار هي نوع من تقنيات التعلم الخاضع للإشراف والتي يتم استخدامها للتصنيف والانحدار. تتخذ هذه الخوارزمية القرارات عن طريق تقسيم البيانات إلى مجموعات أصغر؛ حتى لا يكون هناك المزيد من البيانات. في الواقع، شجرة القرار هي بنية شبيهة بالشجرة تبدأ بالعقدة الجذرية وتتفرع إلى العقد الفرعية. تقوم كل عقدة بتقييم الحالة وتكون أوراق شجرة القرار هي النتائج المحتملة. لنفترض أنك تريد أن تقرر ما سترتديه اليوم. يمكنك البدء باختيار الفستان المناسب من خلال طرح بعض الأسئلة على نفسك:
- هل الجو حار أم بارد في الخارج؟
- هل الجو مشمس أم ممطر؟
- هل سأذهب إلى العمل أو المدرسة؟
كل سؤال هو بمثابة عقدة تقودنا إلى فروع مختلفة. يحتوي كل فرع أيضًا على أوراق تعادل إجابة سؤال. أخيرًا، يتم اتخاذ القرار النهائي عندما نصل إلى الصفحة الأخيرة ولا يكون هناك المزيد من الأسئلة. تعتبر شجرة القرار من أفضل خوارزميات التعلم الآلي، مما يجعلها الخيار الأنسب لحل المشكلات المعقدة.
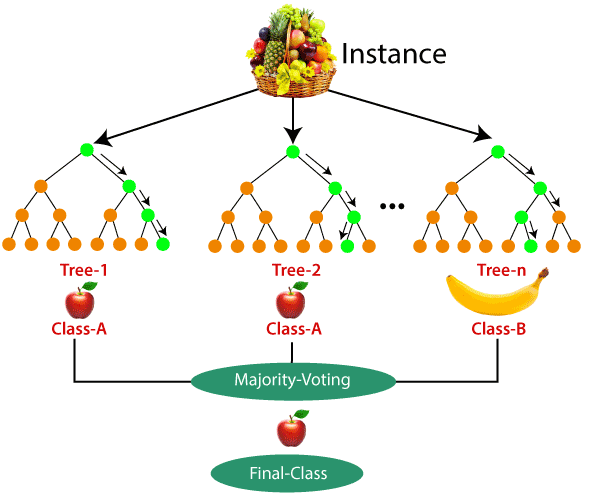
6.Random Forest
إحدى مشكلات شجرة القرار هي صعوبة تعميم المشكلة. لحل هذه المشكلة، تم إنشاء نوع جديد من خوارزميات شجرة القرار عن طريق جمع العديد من الأشجار. في هذه الخوارزمية، التي تُعرف باسم الغابة العشوائية، يتم اتخاذ القرار حول أفضل نتيجة باستخدام نظام تصويت أو حساب متوسط من كل مجموعة. الغابة العشوائية هي نوع من أساليب التعلم الجماعي، حيث تتعاون الأشجار معًا لاتخاذ القرارات والتنبؤات.
تخيل أنك تلعب لعبة الغميضة مع أصدقائك. في هذه اللعبة، تحاول العثور على أفضل مكان للاختباء؛ لذلك تقرر أن تسأل كل واحد من أصدقائك عن رأيه. كل واحد منهم يقدم اقتراحًا مختلفًا. بعض الاقتراحات جيدة وبعضها الآخر ليس كذلك. ولكن إذا استمعت إلى جميع الاقتراحات وأخذت متوسطها، فمن المحتمل أن تجد مكانًا جيدًا للاختباء. الاستماع إلى آراء جميع أصدقائك أفضل من اتخاذ قرار فردي. في الأساس، تعمل خوارزمية الغابة العشوائية بالطريقة نفسها. فهي تجمع مجموعة من أشجار القرار وتأخذ متوسط توقعاتهم، مما يجعل خوارزمية الغابة العشوائية أكثر دقة من شجرة القرار.
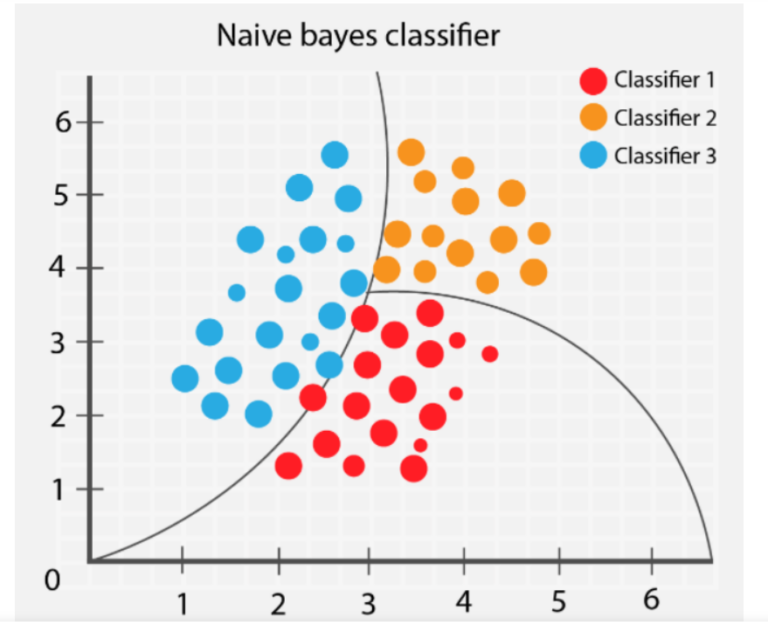
7.Naive Bayes
خوارزمية (Naive Bayes) هي خوارزمية تعلم آلي تعتمد على نظرية بايز وتُستخدم للتصنيف. تعمل هذه الخوارزمية على فرضية أن خصائص نقطة البيانات مستقلة عن بعضها البعض. تعتمد طريقة عمل بايز البسيط على حساب احتمال أن تنتمي نقطة البيانات إلى فئة معينة بناءً على احتمالية كل واحدة من خصائص تلك النقطة المتعلقة بهذه الفئة. لفهم هذه الفكرة بشكل أوضح، دعنا نأخذ مثالًا توضيحيًا.
تخيل أن لديك كيسًا من الفواكه وتريد أن تعرف ما إذا كان يحتوي على تفاح أو برتقال. يمكنك استخدام خوارزمية بايز البسيط للتنبؤ بذلك عن طريق حساب احتمالية أن تكون كل واحدة من خصائص الفاكهة (مثل اللون، الشكل، الحجم) تنتمي إلى فئة معينة (تفاح أو برتقال). على سبيل المثال، تعلم أن التفاح غالبًا ما يكون مستديرًا ولونه أحمر، في حين أن البرتقال غالبًا ما يكون برتقالي اللون وبيضاوي الشكل. يمكنك استخدام هذه المعلومات لحساب احتمال أن تكون الفاكهة في كيسك تفاحة أو برتقالة. تنظر خوارزمية بايز البسيط إلى كل الخصائص بشكل مستقل، لكنها في النهاية تجمعها معًا لتحديد الفئة التي تنتمي إليها المتغيرات.
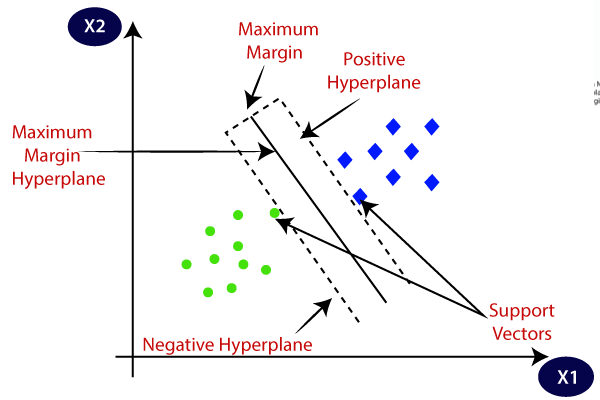
8.SVM (Support Vector Machine)
خوارزمية (SVM) هي واحدة من الخوارزميات المفيدة للتصنيف والتنبؤ بالمهام، حتى عندما نواجه كمية صغيرة من البيانات. تعمل SVM على إيجاد Hyperplane يفصل نقاط البيانات في مجموعة إلى قسمين. الهدف من SVM هو إنشاء أفضل خط أو حد قرار يمكنه تقسيم الفضاء ذو الأبعاد المتعددة (n-dimensional space) إلى فئات، بحيث يمكننا بسهولة تصنيف نقطة البيانات الجديدة في الفئة الصحيحة. يُطلق على هذا الحد الفاصل الأفضل اسم Hyperplane.
تخيل أن لدينا مجموعة بيانات من صور للقطط والكلاب. نقوم أولاً بتدريب النموذج باستخدام مجموعة صور للحيوانين، بحيث يتعرف النموذج على الخصائص المختلفة للقطط والكلاب. يقوم خوارزمية SVM بإيجاد خط (Hyperplane) يفصل صور القطط عن صور الكلاب في مجموعة البيانات. بعد ذلك، يمكن للنموذج عند مشاهدة صور جديدة أن يحدد ما إذا كانت الصورة الجديدة تخص قطة أو كلبًا.
9.Apriori
خوارزمية (Apriori) هي واحدة من خوارزميات (Rule Based) وتُستخدم لاكتشاف الخصائص المتكررة للعناصر في مجموعة بيانات. غالبًا ما تُستخدم هذه الخوارزمية لتحليل سلة مشتريات العملاء، حيث يكون الهدف هو العثور على العلاقات بين العناصر التي تُشترى معًا بشكل متكرر. تعمل أبريوري من خلال بناء مجموعات عناصر أكبر بشكل متكرر من مجموعات أصغر. يبدأ التنبؤ بالأنماط بأصغر مجموعات ممكنة من العناصر، وهي العناصر الفردية. ثم تقوم الخوارزمية بدمج مجموعات العناصر مع بعضها لتكوين مجموعات أكبر. يستمر هذا النهج حتى نصل إلى حد معين من الحجم أو لم يعد بالإمكان العثور على مجموعات عناصر متكررة.
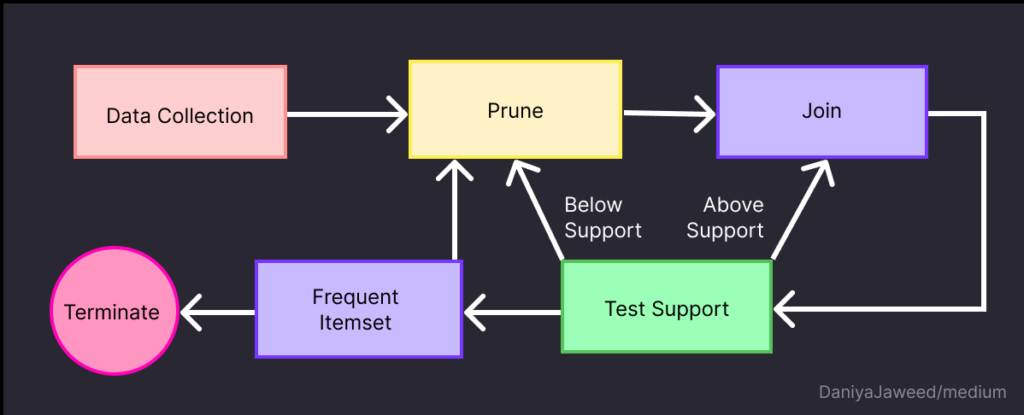
تخيل أن لديك مجموعة بيانات من معاملات متجر بقالة. كل معاملة تحتوي على العناصر التي اشتراها العميل. الخطوة الأولى في هذه الخوارزمية هي جمع البيانات (Data Collection)، حيث تقوم الخوارزمية بجمع البيانات. الآن، الخطوة الأولى هي جمع العناصر المشتراة من المتجر، والنتيجة كما يلي:
– الشراء الأول: طماطم، بروكلي، لحم
– الشراء الثاني: طماطم، خبز
– الشراء الثالث: برتقال، بروكلي، خبز، لحم
– الشراء الرابع: طماطم، خبز
– الشراء الخامس: برتقال، بروكلي، خبز
بعد ذلك، تقوم خوارزمية أبريوري بعدّ كل عنصر، والنتيجة كالتالي:
– طماطم: 3
– بروكلي: 3
– لحم: 2
– خبز: 4
– برتقال: 2
في الخطوة الثانية، يجب تحديد الحد الأدنى لدعم التكرار (Minimum Support Threshold) لتحديد مجموعات العناصر المتكررة. لنفترض أن الحد الأدنى هو 3. هذا يعني أن مجموعة العناصر يجب أن تظهر في ثلاث معاملات على الأقل لكي نعتبرها متكررة. العناصر التي ظهرت أقل من ثلاث مرات يتم حذفها (Prune)، ويتم دمج العناصر المتكررة معًا (Join). في الخطوة الثالثة، تحسب الخوارزمية العناصر المتكررة (التي تكررت 3 مرات على الأقل) وتعرض النتيجة التالية:
– {طماطم}: 3 (متكرر)
– {بروكلي}: 3 (متكرر)
– {لحم}: 2 (غير متكرر)
– {خبز}: 4 (متكرر)
– {برتقال}: 2 (غير متكرر)
في الخطوة الرابعة، تحسب الخوارزمية أزواج العناصر المتكررة ذات الطول 2 باستخدام مجموعات العناصر المتكررة من الخطوة السابقة، والنتيجة كما يلي. تُسمى هذه الخطوة اختبار الدعم (Test Support):
– {طماطم، بروكلي}: 2 (غير متكرر)
– {طماطم، لحم}: 1 (غير متكرر)
– {طماطم، خبز}: 3 (متكرر)
– {طماطم، برتقال}: 1 (غير متكرر)
– {بروكلي، لحم}: 1 (غير متكرر)
– {بروكلي، خبز}: 2 (غير متكرر)
– {بروكلي، برتقال}: 1 (غير متكرر)
– {لحم، خبز}: 1 (غير متكرر)
– {لحم، برتقال}: 1 (غير متكرر)
– {خبز، برتقال}: 2 (غير متكرر)
في الخطوة الخامسة، نكرر العملية، لكن هذه المرة مع مجموعات عناصر بطول 3، 4، وهكذا، حتى لا يتم العثور على مجموعات عناصر متكررة أخرى.
في هذا المثال، سنكتفي بالطول 2. هذه هي خطوة مجموعات العناصر المتكررة (Frequent Itemset) بناءً على ذلك، مجموعات العناصر المتكررة تشمل:
– طماطم
– بروكلي
– خبز
هذه المجموعات تُظهر العناصر التي تُشترى معًا بشكل متكرر. في النهاية، تصل الخوارزمية إلى مرحلة الإنهاء (Terminate)، وهي المرحلة التي لا يجب فيها إنتاج مجموعات عناصر جديدة. باستخدام هذه المعلومات، يمكن لمتجر البقالة اتخاذ قرارات استراتيجية مثل وضع التفاح والبروكلي والخبز بالقرب من بعضهم البعض لتشجيع المزيد من المبيعات.
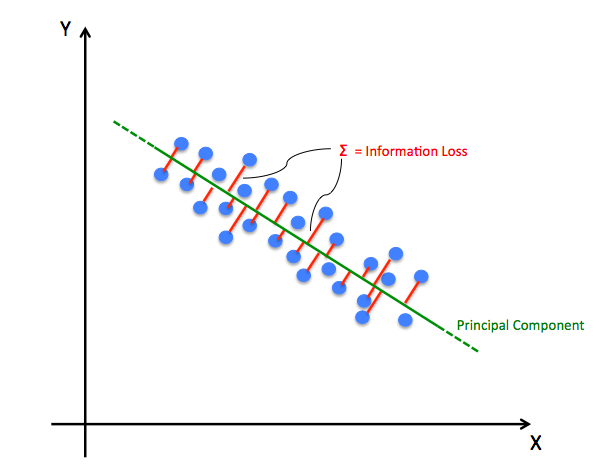
10.PCA (Principal Component Analysis)
خوارزمية تعلم الآلة تحليل المكونات الرئيسية (PCA) تُستخدم لتقليل أبعاد مجموعة البيانات وتبسيط معالجة المعلومات. تقليل الأبعاد هو عملية تقليل عدد الخصائص في مجموعة بيانات دون فقدان كبير للمعلومات. تحتفظ هذه الخوارزمية بالمكونات الرئيسية لمجموعة البيانات وتزيل الميزات الجديدة التي لا ترتبط بهذه المجموعة. يتم هذا الحذف بطريقة تحافظ على تباين البيانات قدر الإمكان. على سبيل المثال، قد تلاحظ خوارزمية PCA أن طول ووزن الحيوانات مرتبطان بشكل كبير. هذا يعني أننا نستطيع استخدام خاصية واحدة مثل الطول لتمثيل كل من الطول والوزن.
ما نقرأه في خوارزميات التعلم الآلي
مع تزايد حجم البيانات، يبدو من الضروري استخدام أسرع خوارزميات التعلم الآلي. تُستخدم خوارزميات التعلم الآلي في التصنيف والتنبؤ والحسابات. يتم استخدام كل واحد منهم في حالات محددة وله كفاءة أكبر. تتيح هذه الخوارزميات إمكانية العثور على المعلومات الضرورية بين مجموعة كبيرة من البيانات؛ هذا غير ممكن يدويا.
الأسئلة المتداولة
أي خوارزمية أسرع؟
سرعة خوارزمية الغابة العشوائية وخوارزميات شجرة القرار أعلى في معالجة المعلومات الطويلة؛ بينما تعتبر خوارزمية Naive Bayes أسرع من حيث زمن التنفيذ.
أيهما أسهل لبدء التعلم؟
يعتمد اختيار أبسط خوارزمية لبدء التعلم على التفضيلات الفردية؛ لكن الانحدار الخطي والانحدار اللوجستي وخوارزميات KNN أسهل في البدء في التعلم.
ما هي أفضل خوارزمية التعلم الآلي للتنبؤ؟
يعتمد اختيار أفضل خوارزمية تنبؤ على عوامل مثل طبيعة المشكلة ونوع البيانات والمتطلبات الفريدة. تعد خوارزميات SVM والغابات العشوائية أكثر شيوعًا للتنبؤ.
